Using Deep Q-Learning in FIFA 18 to perfect the art of free-kicks
Chintan Trivedi
15 Jun 2018
•
13 min read

A code tutorial in Tensorflow that uses Reinforcement Learning to take free kicks.

Free-kicks taken by the AI bot, trained through 1000 epochs of the Reinforcement Learning process.
In my previous article, I presented an AI bot trained to play the game of FIFA using Supervised Learning technique. With this approach, the bot quickly learnt the basics of the game like passing and shooting. However, the training data required to improve it further quickly became cumbersome to gather and provided little-to-no improvements, making this approach very time consuming. For this sake, I decided to switch to Reinforcement Learning, as suggested by almost everyone who commented on that article!
Previous article: Building a Deep Neural Network to play FIFA 18
In this article, I’ll provide a short description of what Reinforcement Learning is and how I applied it to this game. A big challenge in implementing this is that we do not have access to the game’s code, so we can only make use of what we see on the game screen. Due to this reason, I was unable to train the AI on the full game, but could find a work-around to implement it for skill games in practice mode. For this tutorial, I will be trying to teach the bot to take 30-yard free kicks, but you can modify it to play other skill games as well. Let’s start with understanding the Reinforcement Learning technique and how we can formulate our free kick problem to fit this technique.
What is Reinforcement Learning (and Deep Q-Learning)?
Contrary to Supervised Learning, we do not need to manually label the training data in Reinforcement Learning. Instead, we interact with our environment and observe the outcome of our interaction. We repeat this process multiple times gaining examples of positive and negative experiences, which acts as our training data. Thus, we learn by experimentation and not imitation.
Let’s say our environment is in a particular state s, and upon taking an action a, it changes to state s’. For this particular action, the immediate reward you observe in the environment is r. Any set of actions that follow this action will have their own immediate rewards, until you stop interacting due to a positive or a negative experience. These are called future rewards. Thus, for the current state s, we will try to estimate out of all actions possible which action will fetch us the maximum immediate + future reward, denoted by Q(s,a) called the Q-function. This gives us Q(s,a) = r + γ * Q(s’,a’) which denotes the expected final reward by taking action a in state s. Here, γ is a discount factor to account for uncertainty in predicting the future, thus we want to trust the present a bit more than the future.
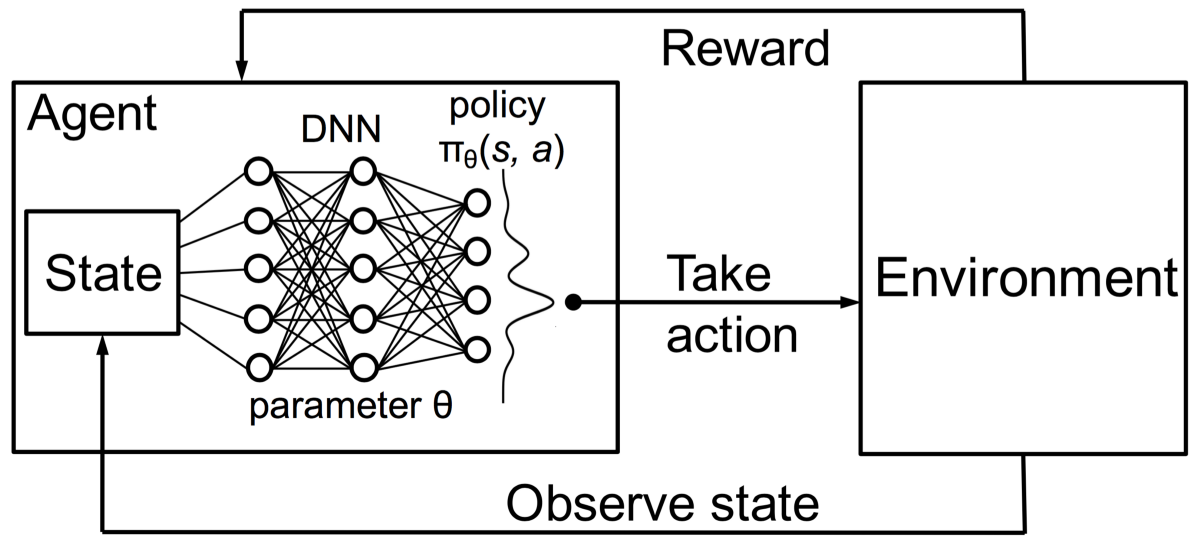
Deep Q-learning is a special type of Reinforcement Learning technique where the Q-function is learnt by a deep neural network. Given the environment’s state as an image input to this network, it tries to predict the expected final reward for all possible actions like a regression problem. The action with the maximum predicted Q-value is chosen as our action to be taken in the environment. Hence the name Deep Q-Learning.
Formulating free-kicks in FIFA as a Q-Learning problem
- States: Screenshot images of the game processed through a MobileNet CNN giving
128-dimensional flattened feature map. - Actions: Four possible actions to take
shoot_low, shoot_high, move_left, move_right. - Reward: If upon pressing shoot, in-game score increases by more than 200, we scored a goal so
r=+1. If we missed the goal, score remains the same sor=-1. Finally,r=0for actions related to moving left or right. - Policy: Two-layered Dense Network that takes feature map as input and predicts total final reward for all 4 actions.
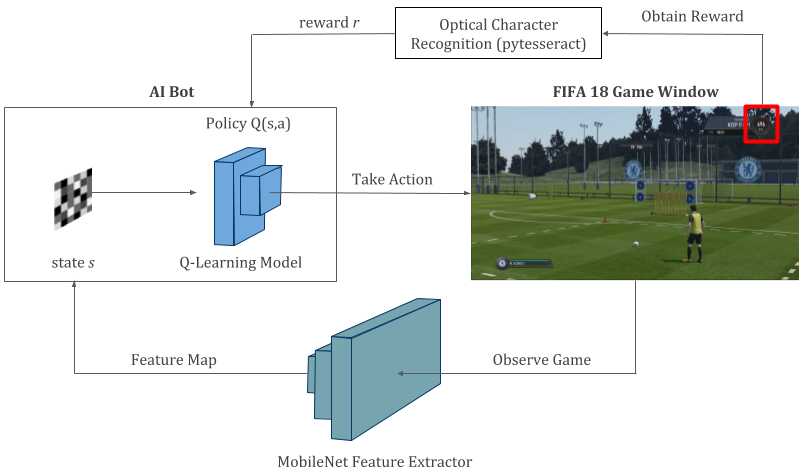
Note: If we had a performance meter in kick-off mode of FIFA like there is in the practice mode, we might have been able to formulate this problem for playing the entire game and not restrict ourselves to just taking free-kicks. That, or we need access to game’s internal code which we don’t have. Anyways, let’s make the most of what we do have.
Results
While the bot has not mastered all different kinds of free kicks, it has learnt some situations very well. It almost always hits the target in absence of wall of players but struggles in its presence. Also, when it hasn’t encountered a situation frequently in training like not facing the goal, it behaves bonkers. However, with every training epoch, this behavior was noticed to decrease on an average.
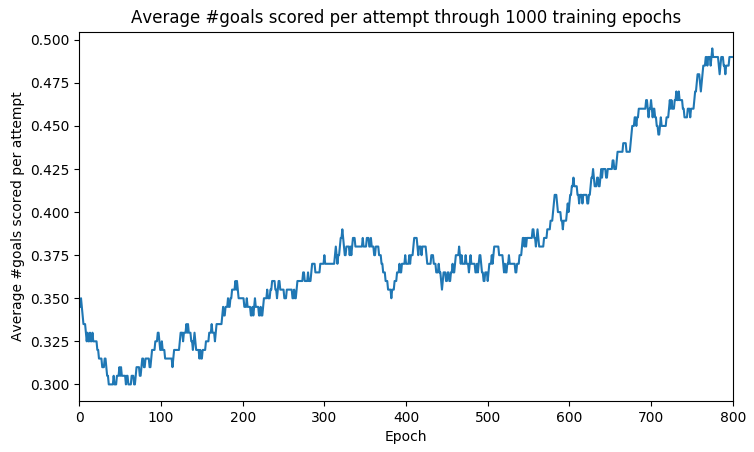
As shown in the figure above, the average goal scoring rate grows from 30% to 50% on an average after training for 1000 epochs. This means the current bot scores about half of the free kicks it attempts (for reference, a human would average around 75–80%). Do consider that FIFA tends to behave non-deterministically which makes learning very difficult.
 Good examples of free kicks (model trained till 1000 epochs). The bot almost always scores in absence of the yellow player cutouts blocking the goal. In presence of the player wall, it gives mixed results.
Good examples of free kicks (model trained till 1000 epochs). The bot almost always scores in absence of the yellow player cutouts blocking the goal. In presence of the player wall, it gives mixed results.
 Bad examples of free kicks. In some cases like above, the bot keeps transitioning between two states by alternating between left and right actions, making it stuck in a never ending loop. Probably a weakness of Reinforcement Learning setup.
Bad examples of free kicks. In some cases like above, the bot keeps transitioning between two states by alternating between left and right actions, making it stuck in a never ending loop. Probably a weakness of Reinforcement Learning setup.
More results in video format can be found on my YouTube channel, with the video embedded below. Please subscribe to my channel if you wish to keep track of all my projects.
I would recommend below gists of code only for the purpose of understanding this tutorial since some lines have been removed for brevity. Please use the full code from git while running it. Let’s go over the 4 main parts of the code.
1. Interacting with the game environment
We do not have any readymade API available that gives us access to the code. So, let’s make our own API instead! We’ll use game’s screenshots to observe the state, simulated key-presses to take action in the game environment and Optical Character Recognition to read our reward in the game. We have three main methods in our FIFA class: observe(), act(), _get_reward() and an additional method is_over() to check if the free kick has been taken or not.
class FIFA(object):
"""
This class acts as the intermediate "API" to the actual game. Double quotes API because we are not touching the
game's actual code. It interacts with the game simply using screen-grab (input) and keypress simulation (output)
using some clever python libraries.
"""
# Define actions that our agent can take and the corresponding keys to press for taking that action.
actions_display_name = ['shoot low', 'shoot high', 'move left', 'move right']
key_to_press = [spacebar, spacebar, leftarrow, rightarrow]
# Initialize reward that will act as feedback from our interactions with the game
self.reward = 0
def __init__(self):
# Create a CNN graph object that will process screenshot images of the game.
self.cnn_graph = CNN()
# Observe our game environment by taking screenshot of the game.
def observe(self):
# Get current state s from screen using screen-grab and narrow it down to the game window.
screen = grab_screen(region=None)
game_screen = screen[25:-40, 1921:]
# Process through CNN to get the feature map from the raw image. This will act as our current state s.
return self.cnn_graph.get_image_feature_map(game_screen)
# Press the appropriate key based on the action our agent decides to take.
def act(self, action):
# If we are shooting low (action=0) then press spacebar for just 0.05s for low power.
# In all other cases press the key for a longer time.
PressKey(key_to_press[action])
time.sleep(0.05) if action == 0 else time.sleep(0.2)
ReleaseKey(key_to_press[action])
# Wait until some time after taking action for the game's animation to complete.
# Taking a shot requires 5 seconds of animation, otherwise the game responds immediately.
time.sleep(5) if action in [0, 1] else time.sleep(1)
# Once our environment has reacted to our agent's actions, we fetch the reward
# and check if the game is over or not (ie, it is over once the shot been taken)
reward = self._get_reward(action)
game_over = self._is_over(action)
return self.observe(), reward, game_over
# Get feedback from the game - uses OCR on "performance meter" in the game's top right corner.
# We will assign +1 reward to a shot if it ends up in the net, a -1 reward if it misses the net
# and 0 reward for a left or right movement.
def _get_reward(self, action):
screen = grab_screen(region=None)
game_screen = screen[25:-40, 1921:]
# Narrow down to the reward meter at top right corner of game screen to get the feedback.
reward_meter = game_screen[85:130, 1650:1730]
i = Image.fromarray(reward_meter.astype('uint8'), 'RGB')
try:
# Use OCR to recognize the reward obtained after taking the action.
ocr_result = pt.image_to_string(i)
ingame_reward = int(''.join(c for c in ocr_result if c.isdigit()))
# Determine if the feedback is positive or not based on the reward observed.
# Also update our reward object with latest observed reward.
if ingame_reward - self.reward > 200:
# If ball goes into the net, our ingame performance meter increases by more than 200 points.
self.reward = ingame_reward
action_reward = 1
elif self._is_over(action):
# If ball has been shot but performance meter has not increased the score, ie, we missed the goal.
self.reward = ingame_reward
action_reward = -1
else:
# If ball hasn't been shot yet, we are only moving left or right.
self.reward = ingame_reward
action_reward = 0
except:
# Sometimes OCR fails, we will just assume we haven't scored in this scenario.
action_reward = -1 if self._is_over(action) else 0
return action_reward
def _is_over(self, action):
# Check if the ball is still there to be hit. If shoot action has been initiated,
# the game is considered over since you cannot influence it anymore.
return True if action in [0, 1] else False
2. Collecting training data
Throughout the training process, we want to store all our experiences and observed rewards. We will use this as the training data for our Q-Learning model. So, for every action we take, we store the experience <s, a, r, s’> along with a game_over flag. The target label that our model will try to learn is the final reward for each action which is a real number for our regression problem.
class ExperienceReplay(object):
"""
During gameplay all the experiences < s, a, r, s’ > are stored in a replay memory.
In training, batches of randomly drawn experiences are used to generate the input and target for training.
"""
def __init__(self, max_memory=100000, discount=.9):
"""
Setup
max_memory: the maximum number of experiences we want to store
memory: a list of experiences
discount: the discount factor for future experience
In the memory the information whether the game ended at the state is stored seperately in a nested array
[...
[experience, game_over]
[experience, game_over]
...]
"""
self.max_memory = max_memory
self.memory = list()
self.discount = discount
def remember(self, states, game_over):
# Save a state to memory
self.memory.append([states, game_over])
# We don't want to store infinite memories, so if we have too many, we just delete the oldest one
if len(self.memory) > self.max_memory:
del self.memory[0]
def get_batch(self, model, batch_size=10):
# How many experiences do we have?
len_memory = len(self.memory)
# Calculate the number of actions that can possibly be taken in the game.
num_actions = model.output_shape[-1]
# Dimensions of our observed states, ie, the input to our model.
env_dim = self.memory[0][0][0].shape[1]
# We want to return an input and target vector with inputs from an observed state.
inputs = np.zeros((min(len_memory, batch_size), env_dim))
# ...and the target r + gamma * max Q(s’,a’)
# Note that our target is a matrix, with possible fields not only for the action taken but also
# for the other possible actions. The actions not take the same value as the prediction to not affect them
targets = np.zeros((inputs.shape[0], num_actions))
# We draw states to learn from randomly
for i, idx in enumerate(np.random.randint(0, len_memory,
size=inputs.shape[0])):
"""
Here we load one transition <s, a, r, s’> from memory
state_t: initial state s
action_t: action taken a
reward_t: reward earned r
state_tp1: the state that followed s’
"""
state_t, action_t, reward_t, state_tp1 = self.memory[idx][0]
# We also need to know whether the game ended at this state
game_over = self.memory[idx][1]
# add the state s to the input
inputs[i:i + 1] = state_t
# First we fill the target values with the predictions of the model.
# They will not be affected by training (since the training loss for them is 0)
targets[i] = model.predict(state_t)[0]
"""
If the game ended, the expected reward Q(s,a) should be the final reward r.
Otherwise the target value is r + gamma * max Q(s’,a’)
"""
# Here Q_sa is max_a'Q(s', a')
Q_sa = np.max(model.predict(state_tp1)[0])
# if the game ended, the reward is the final reward
if game_over: # if game_over is True
targets[i, action_t] = reward_t
else:
# r + gamma * max Q(s’,a’)
targets[i, action_t] = reward_t + self.discount * Q_sa
return inputs, targets
- Training process
Now that we can interact with the game and store our interactions in memory, let’s start training our Q-Learning model. For this, we will attain a balance between exploration (taking a random action in the game) and exploitation (taking action predicted by our model). This way we can perform trial-and-error to obtain different experiences in the game. The parameter
epsilonis used for this purpose, which is an exponentially decreasing factor that balances exploration and exploitation. In the beginning, when we know nothing, we want to do more exploration but as number of epochs increases and we learn more, we want to do more exploitation and less exploration. Hence. the decaying value of theepsilonparameter.
For this tutorial, I have only trained the model for 1000 epochs due to time and performance constraints, but in the future, I would like to push it to at least 5000 epochs.
# parameters
max_memory = 1000 # Maximum number of experiences we are storing
batch_size = 1 # Number of experiences we use for training per batch
exp_replay = ExperienceReplay(max_memory=max_memory)
# Train a model on the given game
def train(game, model, epochs, verbose=1):
num_actions = len(game.key_to_press) # 4 actions [shoot_low, shoot_high, left_arrow, right_arrow]
# Reseting the win counter
win_cnt = 0
# We want to keep track of the progress of the AI over time, so we save its win count history
# indicated by number of goals scored
win_hist = []
# Epochs is the number of games we play
for e in range(epochs):
loss = 0.
# epsilon for exploration - dependent inversely on the training epoch
epsilon = 4 / ((e + 1) ** (1 / 2))
game_over = False
# get current state s by observing our game environment
input_t = game.observe()
while not game_over:
# The learner is acting on the last observed game screen
# input_t is a vector containing representing the game screen
input_tm1 = input_t
# We choose our action from either exploration (random) or exploitation (model).
if np.random.rand() <= epsilon:
# Explore a random action
action = int(np.random.randint(0, num_actions, size=1))
else:
# Choose action from the model's prediction
# q contains the expected rewards for the actions
q = model.predict(input_tm1)
# We pick the action with the highest expected reward
action = np.argmax(q[0])
# apply action, get rewards r and new state s'
input_t, reward, game_over = game.act(action)
# If we managed to score a goal we add 1 to our win counter
if reward == 1:
win_cnt += 1
"""
The experiences < s, a, r, s’ > we make during gameplay are our training data.
Here we first save the last experience, and then load a batch of experiences to train our model
"""
# store experience
exp_replay.remember([input_tm1, action, reward, input_t], game_over)
# Load batch of experiences
inputs, targets = exp_replay.get_batch(model, batch_size=batch_size)
# train model on experiences
batch_loss = model.train_on_batch(inputs, targets)
loss += batch_loss
if verbose > 0:
print("Epoch {:03d}/{:03d} | Loss {:.4f} | Win count {}".format(e, epochs, loss, win_cnt))
# Track win history to later check if our model is improving at the game over time.
win_hist.append(win_cnt)
return win_hist
4. Model definition and starting training process
At the heart of the Q-Learning process is a 2-layered Dense/Fully Connected Network with ReLU activation. It takes the 128-dimensional feature map as input state and outputs 4 Q-values for each possible action. The action with the maximum predicted Q-value is the desired action to be taken as per the network’s policy for the given state.
# Number of games played in training.
# Trained on 1000 epochs till now, but would ideally like to train for 5000 epochs at least.
epochs = 1000
game = FIFA()
# Our model's architecture parameters
input_size = 128 # The input shape for model - this comes from the output shape of the CNN Mobilenet
num_actions = len(game.key_to_press)
hidden_size = 512
# Setting up the model with keras.
model = Sequential()
model.add(Dense(hidden_size, input_shape=(input_size,), activation='relu'))
model.add(Dense(hidden_size, activation='relu'))
model.add(Dense(num_actions))
model.compile(sgd(lr=.01), "mse")
# Training the model
hist = train(game, model, epoch, verbose=1)
This is the starting point of execution of this code, but you’ll have to make sure the game FIFA 18 is running in windowed mode on a second display and you load up the free kick practice mode under skill games: shooting menu. Make sure the game controls are in sync with the keys you have hard-coded in the FIFA.py script.
Conclusion
Overall, I think the results are quite satisfactory even though it fails to reach human level of performance. Switching from Supervised to Reinforcement technique for learning helps ease the pain of collecting training data. Given enough time to explore, it performs very well in problems like learning how to play simple games. However, Reinforcement setting seems to fail when it encounters unfamiliar situations, which makes me believe formulating it as a regression problem cannot extrapolate information as well as formulating it as a classification problem in supervised setting. Perhaps a combination of the two could address the weaknesses of both these approaches. Maybe that’s where we’ll see the best results in building AI for games. Something for me to try in the future!
Acknowledgements
I would like to acknowledge this tutorial of Deep Q-Learning and this git repository of gaming with python for providing majority of the code. With the exception of the FIFA “custom-API”, most of the code’s backbone has come from these sources. Thanks to these guys!
Thank you for reading! If you liked Chintan's tutorial, please follow him on medium, github or subscribe to my YouTube channel.

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!