Scaling Deep Learning: Highlights From The Startup.ml Workshop
George Williams
2 May 2018
•
8 min read

TL;DR: I recently attended an all day workshop in San Francisco focused on scaling deep learning - the techniques, the tools, the platforms, the players. I jotted down a few notes and I thought I'd share some of the highlights here.
Some of you are deploying huge deep learning models, with thousands if not millions of parameters. In many cases, you are training a model from scratch, using your own curated training data. As you well know, each stage in this process can be time consuming, from finding the right architecture to finding the right hyper parameters. Training itself can take days or weeks to converge. Finally, the inference side of things can present its own challenges. For example, how do you squeeze a large model you've trained in the cloud, into a mobile device or a Raspberry PI ?
Fortunately, there are now several tricks to scale up the performance of deep learning. These include ways to help you experiment with different architectures, to help you distribute workloads across compute nodes, and even help you optimize models for a native performance boost. Many of these techniques are available now in your favorite deep learning frameworks, like TensorFlow or MXNET. Some advances are so new, that they are only accessible as bleeding edge research, or are only available in custom dedicated hardware. Startup.ml's "Scaling Deep Learning" workshop brought together, in one venue many of the major players in this area, both from research and industry.
The main take aways from the workshop for me were as follows:
- PyTorch is shaping up to be a really great deep learning framework. I think we'll be talking more about it in the coming year.
- TensorFlow provides native graph support for both data and model parallelism across heterogenous compute environments, and can be used to scale models into the billions of parameters.
- Baidu is providing unified deep learning benchmarks across a broad array of deep learning hardware and software stacks.
- Google is opening up their high-performance, dedicated deep learning compute clusters for researchers to use for free.
- Reinforcement learning can guide the automated discovery of novel deep learning architectures.
The remainder of this article summarizes several of the presentations. I've included links and contacts in case you want to dig even deeper into some of the topics presented.
Before getting into that, let me first say that it's pretty exciting that both academia and industry are talking seriously about the production side of deep learning. I've been involved with deep learning for a decade now, first at NYU, then at Apple, now in cybersecurity. It's been great contributing to the growth and evolution of deep learning, from isolated experiments in the lab to massive deployments of mission critical applications. The future of deep learning promises to go even further, extending beyond image, speech, and natural language, into other domains. At my current company, Capsule8, we are focused on cybersecurity and real-time threat detection. We have found that deep and reinforcement learning are extremely useful tools that can complement and bolster a traditionally deterministic security strategy.
OK, enough intro...lets get to the presentation summaries.
Jeremy Howard of fast.ai started things off with a PyTorch tutorial. Jeremy is a great speaker, as he always mixes a little bit of the old with a bit of the new. In his talk, he demoed a PyTorch implementation of the mean-shift algorithm. Mean-shift is an older unsupervised clustering algorithm that uses a KDE-like bandwidth alongside a hill climbing algorithm to find optimal clusters. Jeremy live-coded an example in PyTorch, showing off a nearly 7000 percent GPU speed up after changing one line of code. Mean-shift is of course not deep learning, but the point was to show PyTorch as a highly usable and general machine learning programming language.
It was a great demo, and it's no surprise that Facebook uses it almost exclusively for their machine learning research. Jeremy's demo jupyter notebook is now available and I highly recommend that you play with it. Besides serving as a practical intro to PyTorch, it also contains a mini-lesson on PyTorch tensor broadcasting. If you design your own algorithms from scratch, you should take the time to understand broadcasting. Disciplined use of broadcasting will help you make the most of speedy vectorization operations present in the lower level math libraries and hardware.
Next up was Illia Polosukhin, co-founder at near.ai, formerly from Google Research. If you've spent any time in TensorFlow source code you would likely recognize his name, as he is still one of the most prolific contributors. Illia started out by talking about TensorFlow's builtin support for parallelizing deep learning workloads across CPUs and GPUs, including support for parameter servers, worker tasks, custom communication nodes, and cluster specification. He reviewed the basic types of deep learning parallelism including model parallelism ( where you split the training data across workers ), and model parallelism ( where you split the model itself across workers. ). Illia talked about the challenges of parallelizing a recurrent neural network that contained over 2 billion total parameters !
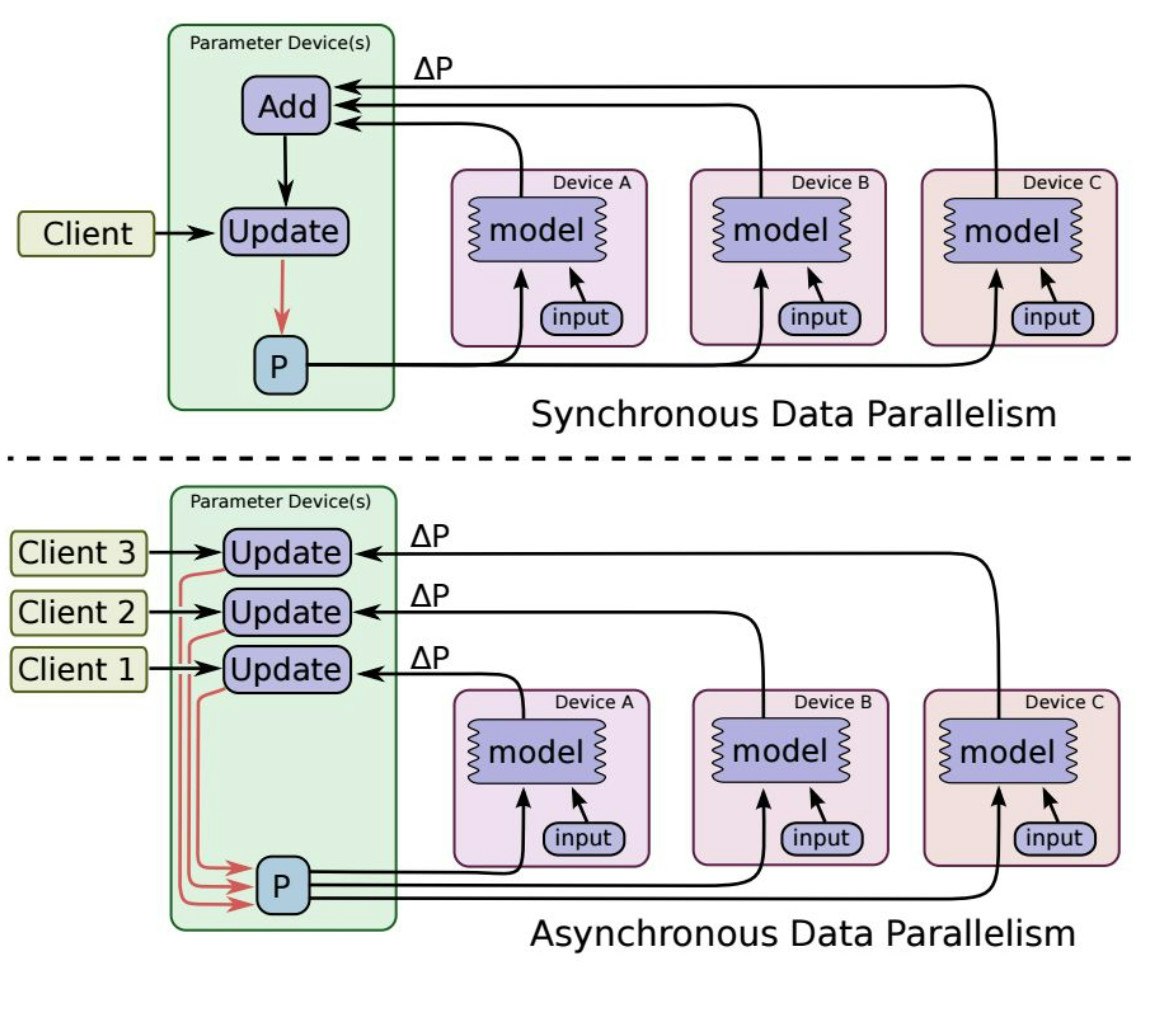
TensorFlow also supports synchronous and asynchronous SGD training. Tuning distributed deep training is not easy. Illia recommends using the timeline profiling tools, using fused operations, recompiling TensorFlow for native machine code speedup, and trying out the XLA JIT. He has provided a bunch of code examples here. He briefly mentioned his new startup near.ai in program synthesis, which you should definitely check out.
Next up was Sharan Narang from Baidu SVAIL, Baidu's Silicon Valley AI Lab. SVAIL boasts an ambitious and aggressive agenda applying deep learning to improve natural user interfaces, including emotion recognition, dialogue systems, speech synthesis, and speech recognition. Research in these areas seem to be moving at a brisk pace, and Baidu is clearly a leader. Anand pointed out that Baidu has moved beyond academic toy speech datasets and has collected their own 11000 hour speech dataset via mechanical Turk. They are also pushing the limits of architecture engineering, including a 115 million parameter GRU-based speech-to-text model for Mandarin Chinese and other languages. A lot more details can be found in their DeepSpeech2 paper.
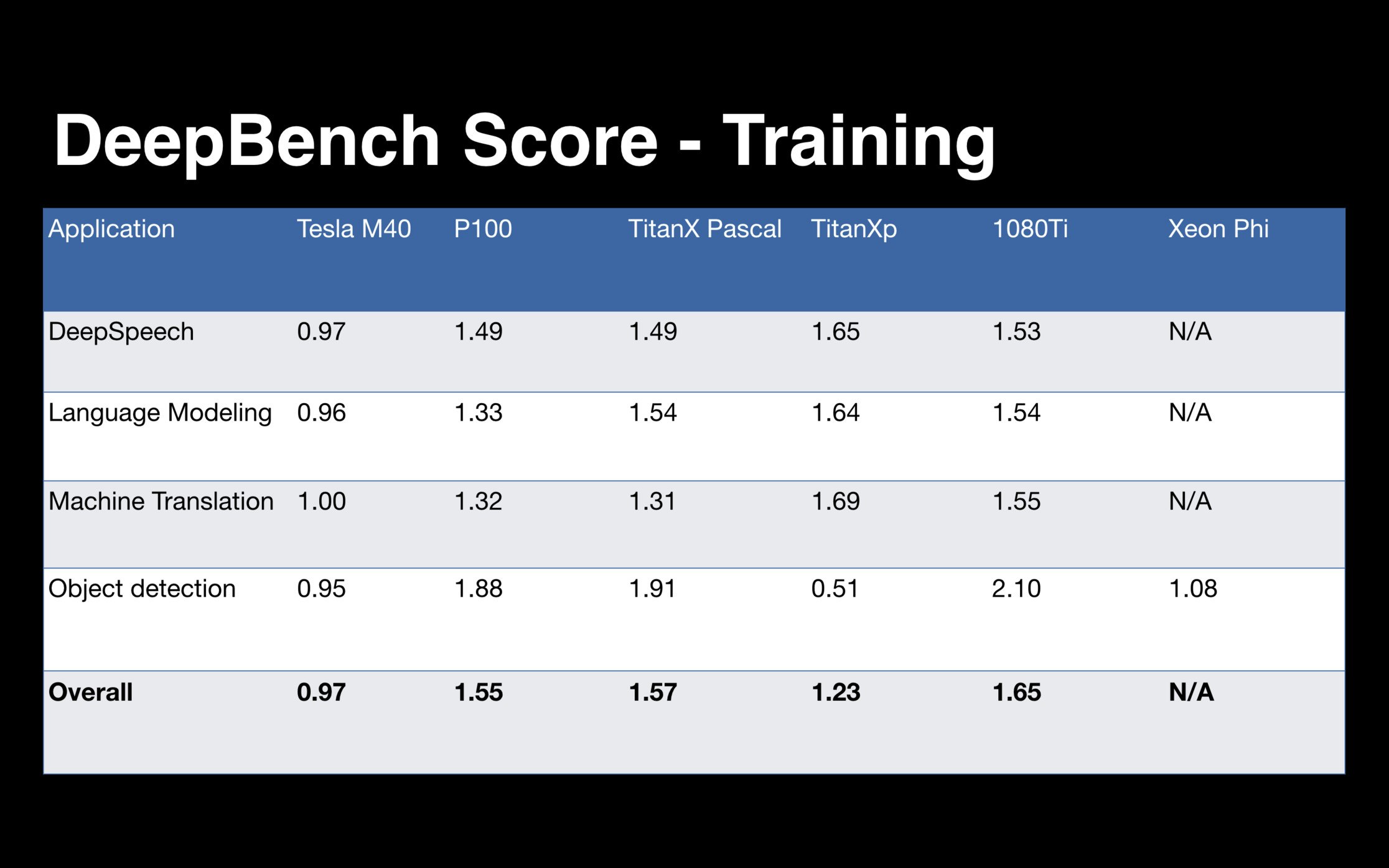
In the second half of the talk, Anand talked about DeepBench. The ambitious scope of this project is to provide an open and fair comparison of common deep learning kernel operations ( matrix multiply, convolutional operations, recurrent operations, etc. ) across a range of deep learning libraries, CPUs, and GPUs. The plan is to eventually encompass a comprehensive set of benchmarks across all deep learning capable hardware and software libraries. Anand described the novel benchmark score they've developed for this purpose, and he showed some examples scores for common algorithms across ARM processors, Nvidia hardware, and even Raspberry PI. DeepBench is open source, so you can compile and run the benchmarking code on your own stack.
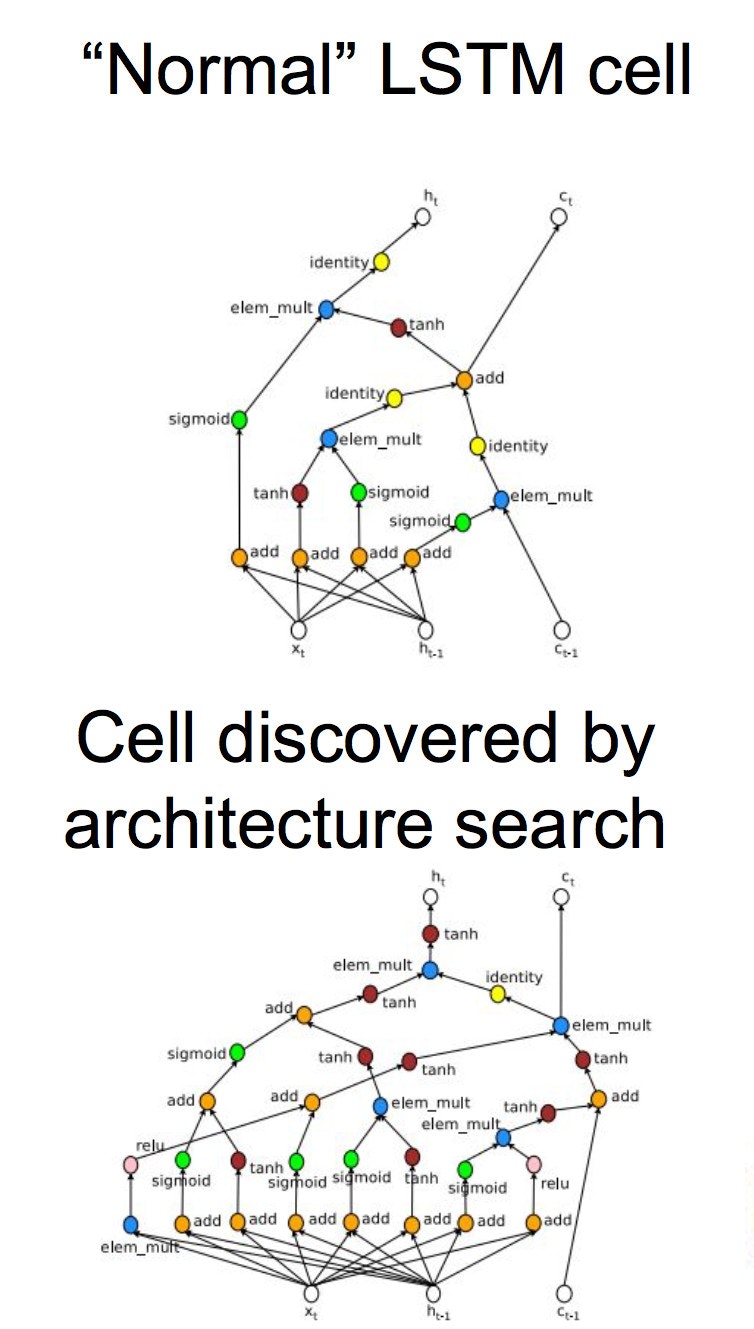
Next was Jonathan Hseu, currently on the Google TensorFlow team. John started his talk with a few meta-learning topics. He did a great job convincing me that we need to have automated approaches to not only search hyper parameters, but also to automate the discovery of novel deep learning architectures. Many high capacity models can take days to converge, a situation that doesn't lend itself to rapid exploration, nor interactive research in deep learning architectures. Google's approach reframes the problem as a search space and they use reinforcement learning as a way to explore it. The technique has already found new types of neural networks and weight update rules. Check out the paper here if you want to learn more. As you might imagine, this kind of exploration is beyond the practical reach of us mere mortals, who don't typically have access to infinite Google resources ( but keep reading for your opportunity ! )
In the next part of his talk, Jonathan talked about TensorFlow support for model and data parallelism, reinforcing many of the points Illia made in his talk. Jonathan added that parallel, asynchronous SGD training is not easy and you should only try it if you know what you are doing ( that has definitely been my experience.) A few other random points that caught my attention: there is contrib code in TensorFlow that can help you take advantage of faster connection technology between compute nodes- this includes InfiniBand and MPI. Also, the latest versions of Kubernetes let you specify a container's GPU resources. Google uses Kubernetes and Docker to serve TensorFlow models via GRPC micro services, in their TensorFlow Serving system.

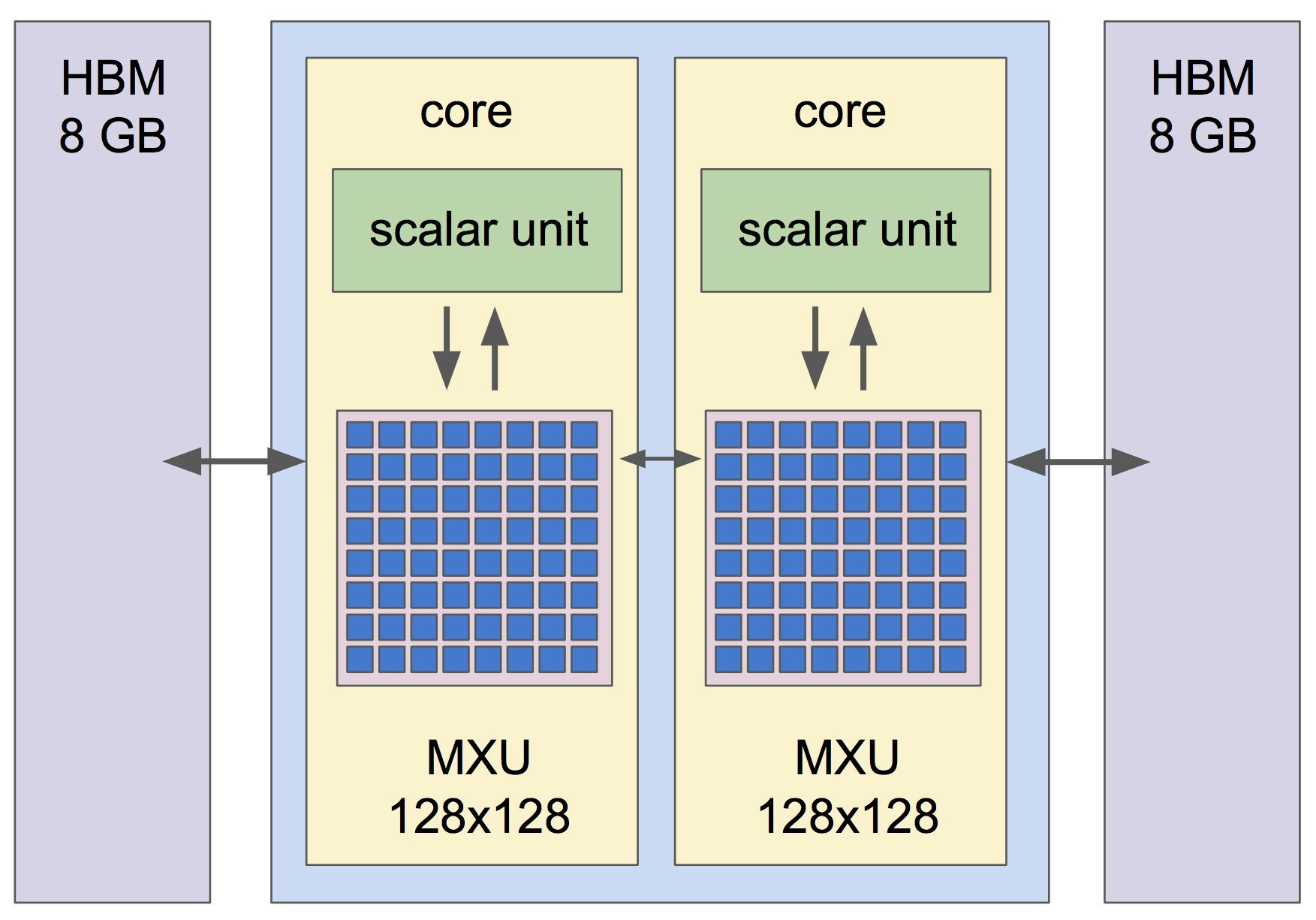
The next part of John's talk was all about the TPU, the tensor processing unit, Google's custom deep learning chip, and it really grabbed everyone's attention. TPUs are programmable as a set of 4 individual chips packed tightly together onto one board. 1 TPU totals 180 teraflops and 64GB of main memory. These TPUs are designed to be interconnected via a 2400 GB/s bus into monstrous TPU “pods” (64 TPU units). A TPU pod represents 11 peta flops of compute ! Lucky for you, Google is making 1000 TPUs available for research. Signup here for your chance to run your TensorFlow models on cutting edge deep learning dedicated hardware.
In the final part of this talk, John mentioned several tricks for optimizing TensorFlow in production. I'll list them briefly here. Take advantage of the XLA JIT to optimize backends for your environment. Use reduced precision floating point when possible ( i.e., evaluate 16 bit, even 8 bit for inferencing to reduce model size.). Experiment with larger batch sizes for training. Use embeddings instead of 1-hot encodings when you can. Do embedding lookups on CPU, not GPU, and hash items that occur rarely. Partition embeddings across parameter servers if that's possible for you.
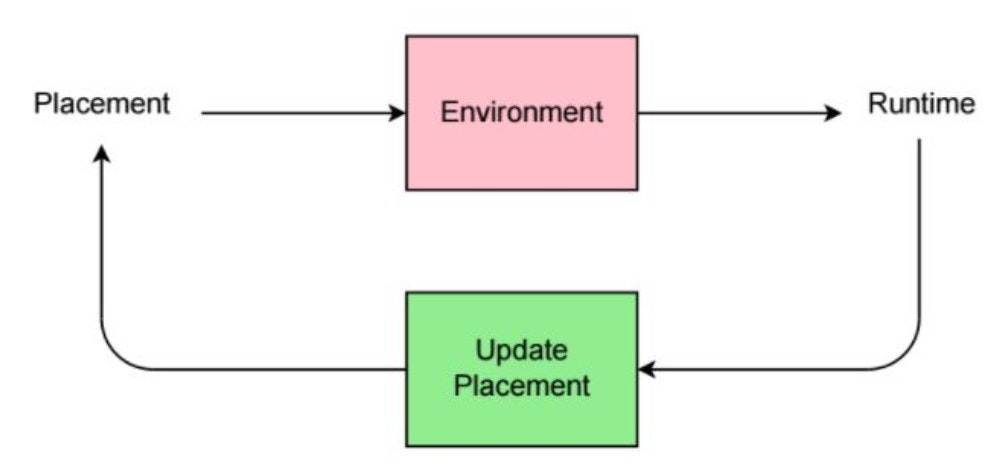
Of course, all this sounds like a lot of hand tuning and the TensorFlow team recognizes this. They've been doing some really cool stuff around automating the parallelization of deep learning work loads, using reinforcement learning to guide the placement of work across compute nodes. For details, see the paper here. This research will start to make its way into TensorFlow, but you will need to use high-level Estimator API to take advantage.
The last three talks were really cool. I'll mention them briefly here and provide relevant links. Boris Ginsburg of Nvidia talked about how to support larger batch size training using a new technique called LARS, layer-wise adaptive rate scheduling. Ryan Sepassi from Google talked about Tensor2Tensor, a project that supports research in novel deep learning-based sequence modeling. Peter Zhokov from Sentient demoed Studio.ML, a data science oriented workbench and machine learning IDE, that facilitates uninterrupted and reproducible machine learning experiments from the laptop to the cloud.
That's it for the presentation summaries. The folks at Startup.ML, including Arshak Navruzyan and Juan Carlos Asensio, hosted yet another great workshop. The content is always interesting and topical, and the speakers are world class researchers and practitioners in machine learning and data science. Its a smaller crowd than a NIPS or an ICML, which I think works really well. It's a lot easier to network with other attendees, and to have informal breakout conversations with the speakers.

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!