Practical Apache Spark in 10 minutes. Part 1 — Ubuntu installation
Igor Bobriakov
21 Sep 2018
•
3 min read

Apache Spark is a powerful open-source processing engine built around speed, ease of use, and sophisticated analytics. It has originally been developed at UC Berkeley in 2009, while Databricks was founded later by the creators of Spark in 2013.
The Spark engine runs in a variety of environments, from cloud services to Hadoop or Mesos clusters. It is used to perform ETL, interactive queries (SQL), advanced analytics (e.g., machine learning) and streaming over large datasets in a wide range of data stores (e.g., HDFS, Cassandra, HBase, S3). Spark supports a variety of popular development languages including Java, Python and Scala.
In this article, we are going to walk you through the installation process of Spark as well as Hadoop which we will need in the future. So follow the instructions to start working with Spark.
Installing Oracle VM Virtualbox
The detailed instruction how to install VM Virtualbox you can read in this article.
But first of all, check if Java is installed on your OS. Please use following short command in your terminal/console to clarify which version of Java is installed on your computer and to avoid version mismatch:
java -version
You can simply move further if your version of Java is 8. If the Java is not installed yet, paste next commands to the cmd:
sudo apt-get update
sudo apt-get install openjdk-8-jdk
Now you can recheck your Java version:
java -version
Hadoop installation
After installing Virtualbox our next step is to install Hadoop for future use. In this article, we are going to show you the installation process only so follow our articles to get a closer look at Hadoop and their integration with Spark.
Hadoop is an open-source software framework for storage and large-scale processing of datasets on clusters of commodity hardware. Follow the instructions and commands below to get it installed:
1 - Download Spark_Hadoop_new.zip file here. 2 - Extract an archive to appropriate folder. 3 - Open the Ubuntu terminal and move to the newly created folder:
cd /path/to/Spark_Hadoop
4 - To change access permissions type the following command next:
sudo chmod 755 setup.sh
5 - As a next step, we’re going to install curl
sudo apt-get install curl
6 - Run an installation next:
sudo ./setup.sh
7 - Hadoop will be installed in your HOME directory. After that, you will find cloudera folder there.
8 - Check if HADOOP_HOME variable was set:
echo $HADOOP_HOME
If not, the response will be blank, and in this case, enter the next command:
source ~/.profile
And check again:
echo $HADOOP_HOME
9 - To start the HDFS and YARN services type
sudo ./start.sh
10 - To check that all services are up and running, check the following URLs:
####HDFS Service:
####YARN Service:
####Note:
Links are local, so they will be available only if you installed everything according to the instruction and everything works as it should.
After installing Hadoop our next step is to install Spark. Let’s do it in few easy steps.
Spark installation
- Download spark package from Spark:
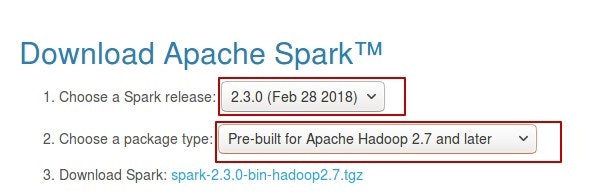
When you click the blue link which is going to redirect you:

And download an encircled package.
- Extract files with the next command:
tar zxvf spark_archive_filename.tgz
- Move to the newly created directory:
cd spark_dir_name
- The next step refers to launching Spark type for certain programming language. Here you can see how to launch Python Skala type:
./bin/pyspark
To launch Spark Scala
./bin/spark-shell
Using Spark
1 - For this example we will use Python Spark. You can launch pyspark by:
./bin/pyspark
2 - Let’s read file README.md.
textfile = sc.textFile("README.md")
This will create an RDD containing one entry per line in the file.
3 - To take a look at first 10 entries in RDD type:
textfile.take(10)
4 - Now, let’s count all the words in this text file.
counts = textfile
.flatMap(lambda line:line.split(" "))
.map(lambda word: (word,1))
.reduceByKey(lambda a, b: a + b)
5 - To take a look on the result:
counts.take(5)
This command will show you first five entries in result.

Conclusion
In this tutorial, we’ve walked through the installation and configuration process of Hadoop and Spark as well as showed you several simple commands to work with PySpark. For further steps in Spark, please take a look at Quick Start guide.
In the next tutorials, we will show you a lot of interesting tasks and tricks to describe how to work with Apache Spark in more details. See you soon!
Don’t forget that you can always download the fully functional virtual machine here vm.datascience-school.com.

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!